
Large Language Models (LLMs) are already changing how work is done in Congress. The House Modernization Committee and its successor, the House Administration Subcommittee on Modernization, have identified a number of ongoing AI initiatives and many areas where AI could contribute to transparency or efficiency. The Subcommittee’s flash reports show a steady increase in the understanding of AI and its potential applications for Congressional work.
Among potential applications, the idea of having AI produce bill summaries always draws a lot of interest – a question related to this topic has been posed at each recent Congressional Data Task force meeting, and the Library of Congress Labs has initiated a project to look into AI-generated summaries. In my view, however, this task is still out of reach for current LLMs, largely because the ‘summaries’ written by the Congressional Research Service (CRS) are not really summaries. They involve a great deal of expertise and understanding of legislative context and are better understood as legislative analyses than summaries. The role of CRS is to place the bill in context of existing law and analyze its likely effects, which sometimes is in contrast with the claims of the bill text or preamble.
Classification of Bills by Legislative Subject Area
I think a much more obvious task for current LLMs is the classification of bills into legislative subject areas. For each bill, CRS identifies a single policy area from among more than 30 policy areas and assigns a list of legislative subject areas from more than 1000 subjects drawn from three different lists. This information is posted on congress.gov (see screenshot below) and is included in the metadata for bills from the Government Publishing Office.
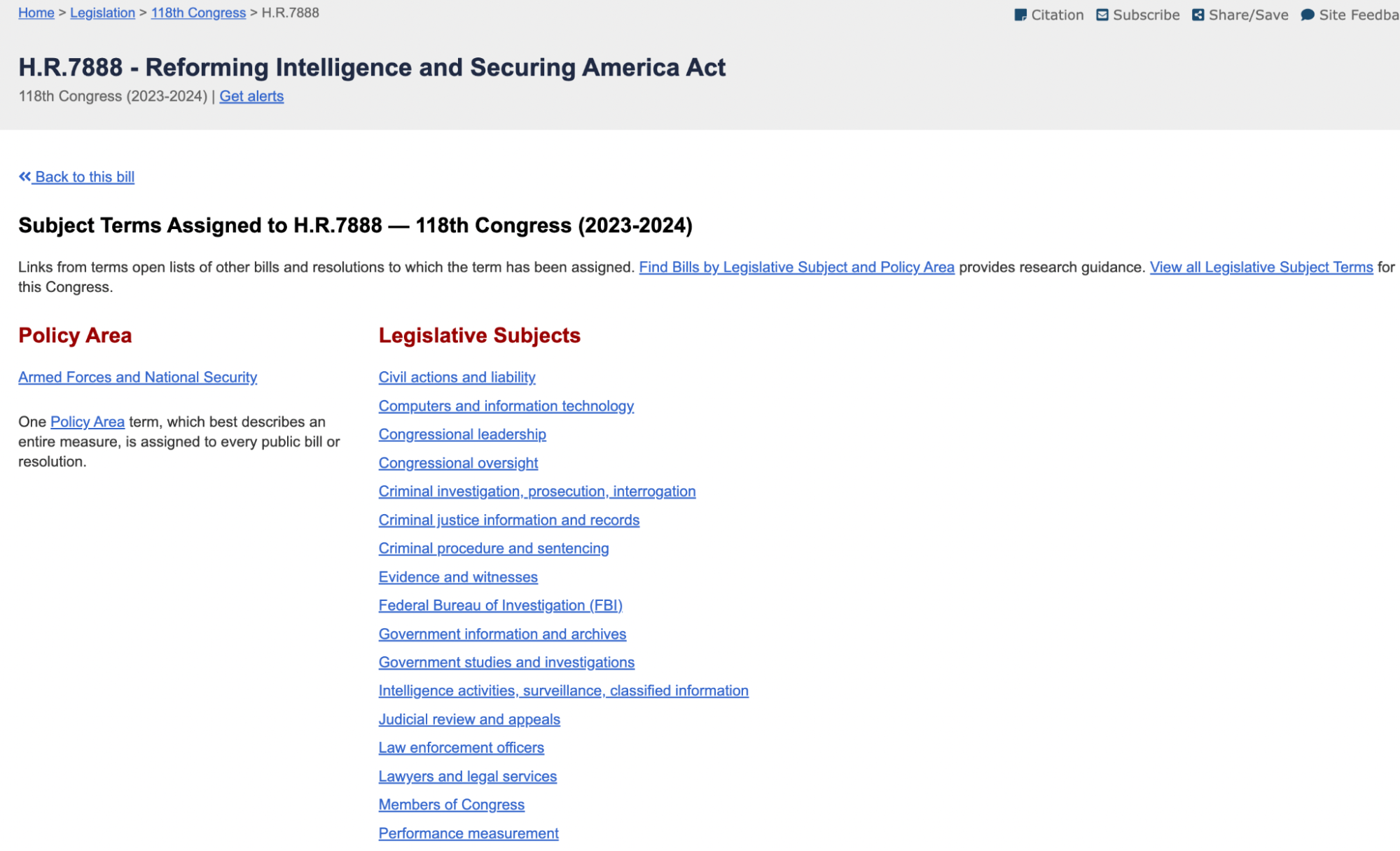
Our engineers at DreamProIT – Andrii Kovalov and Oleksandr Boiko – have built a proof of concept (POC) that relies on the newer large-context language model Claude3 Opus to label a given bill with a list of legislative subject areas. This POC produces measurable results that can be used for both prompt and model evaluation. This ‘one shot’ application of large language models is only going to get better as the models improve. It is also possible to fine-tune the models to get better results, since CRS has tens of thousands of labeled bills, available from public APIs from Congress and the Government Publishing Office.
We’re publishing our preliminary results in this post to encourage others to work in this area. This is a very interesting and relatively straightforward use case for the large-context models. Currently, Anthropic’s Claude3 Opus outperforms Google’s Gemini, GPT-4, Command-R, and other models we’ve tested. Only the first two models have a context window large enough for the largest of bills, which can run into thousands of pages.
Approach
We took a simple approach to this task. We provided the LLMs with a) the policy areas, b) legislative subjects, and c) bill text as context, and prompted the model to return a list of relevant policy areas and legislative subject areas. Our aim was to be overinclusive, with the idea that the output could be further refined by CRS, selecting from a smaller subset of topics to yield the final result. By adjusting the prompt, it was possible to get a larger or smaller set of subject areas to choose from.
In order to ensure that all of the possible subjects could be considered, we tried asking the LLM to list all subject areas and rank their relevance to the bill from 0-10. The risk – which was borne out by our experience – is that LLMs are typically not accurate with quantitative tasks. We saw that the ‘scores’ from this approach were often reasonable (topics with a score of 10 were usually more relevant than those with 0), but not consistent. Some high-scoring items did not have any relation to the bill.
Results
The POC attaches two kinds of labels or classifications to each bill: one policy area and a list of legislative subjects.
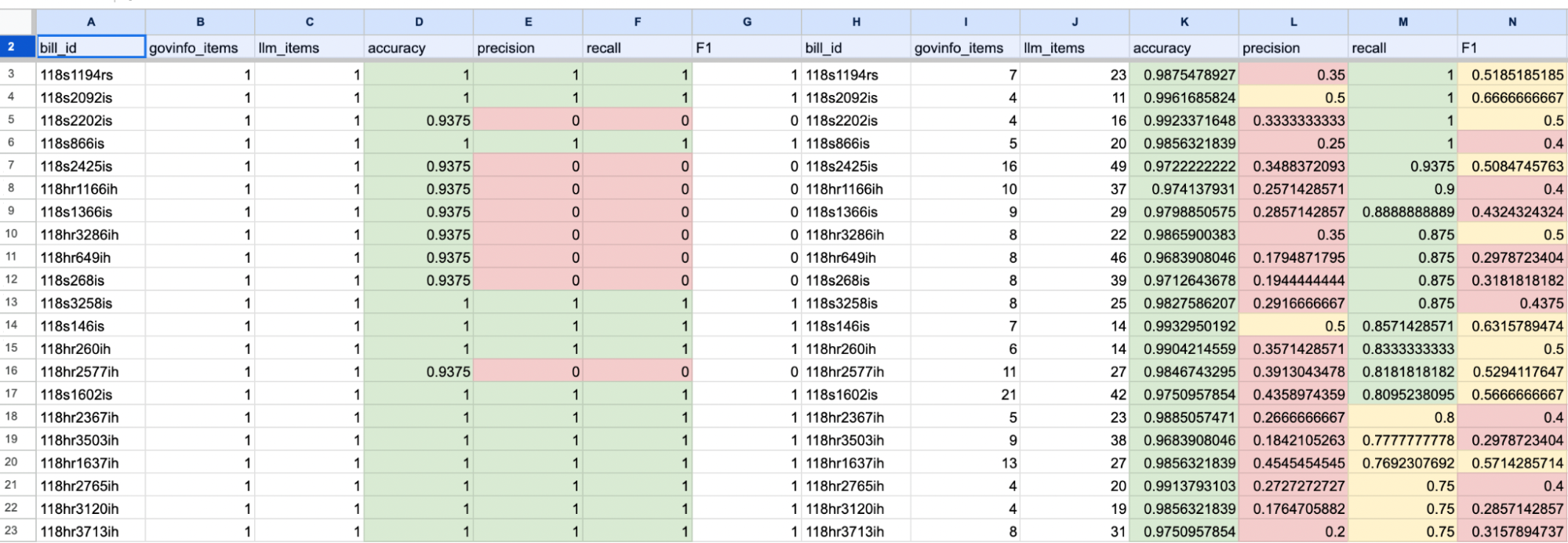
We calculated four metrics for these classifications: accuracy, precision, recall, and F1. You can find more information on these metrics here.
We selected 100 bills and generated a report with the metrics for each bill (see a sample below).
Policy Area
Each bill is assigned only one policy area. Using our prompt, the LLM correctly identified the policy area for 75 out of 100 bills. When we ask the LLM to provide three options, the correct policy area is nearly always among the top three returned: this could simplify the work of analysts in choosing a policy area.
Legislative Subjects
Classifying the legislative subjects related to a bill is more complicated since a) there are thousands of subjects to choose from, many of them similar, and b) each bill may be labeled with many legislative subjects.
One metric, recall, measures how many of the “correct” classifications are included in the list returned by the model. We presume that an analyst will review the model’s results and remove labels that don’t apply. So, getting a high recall score is essential because we don’t want to leave out important labels. We could get a high recall score by returning all of the possible labels. However, that would not be helpful because it would not reduce the analyst’s overhead in selecting the correct labels.
An ideal system will have a very high (nearly 1.0) recall and a pretty good level of precision – not too many false positives.
Example
The Congressional Research Service assigned 5 legislative subjects to bill 118s866, which was introduced in the Senate. Our model returned 20 labels, including all 5 of the ‘correct’ labels. Some of the other 15 subjects may be related to the bill, and an analyst could choose to include them as well, while others have little to no relationship. As intended, our prompt produced a high recall.
In many cases, the model returned all of the correct subjects (recall = 1), with about 50% ‘false positives’. For a given bill, if the CRS identified 20 subjects, the LLM would return between 20 and 80 subjects, including most of the subjects identified by the CRS.
Overall, these results are promising but not stellar. The model does a fairly good job of identifying relevant legislative subjects from among the thousands of possible options. Although it does not consistently identify all relevant subjects and often includes less relevant ones, an application like this could reduce analysts’ burden of categorizing bills by providing fast initial labeling.
Next Steps
Application in Congress
While there are many intellectual and academic reasons to undertake this project, it also could have direct application to the work of Congress. The CRS currently undertakes this task manually, and the legislative subject labels are stored along with bills in their metadata. If these results (or the approaches we suggest) are promising enough, CRS could start to semi-automate the process, providing a smaller list of subjects for analysts to choose from. Eventually, with training of the models and as language models improve, it may be possible to rely entirely on the AI categorization of bills.
Fine Tuning
This task is a good candidate for fine tuning, since there are thousands of labeled bills that can be used for training data. For now, we can train using the models that can handle larger context size or select smaller bills to test a wider range of models. The difference in quality between the current models suggests that improvements of the base models over time may also make the difference in returning better and better results. Currently, Claude3 Opus is the only model that returns reasonably valid classifications with the variety of prompts we attempted.
Traditional Text Classification
The results we accomplished with LLMs may be possible with more traditional text classification techniques. Text classification long predates large language models, and there are many options for training classifiers. However, there are some features of this task that make it a challenge for traditional classification techniques including:
- Variation in bill size
- Very large bills
- The large number of possible classification categories (> 1000) and the large overlap between them.
All of these obstacles may be possible to overcome, particularly since there is ample training data, produced by the experts at CRS. It would be interesting to try a variety of approaches (chunking bills by page or section; vectorization; using a recurrent neural network for classification) and compare the output to LLMs.